Stable Diffusion XL 本地部署AI圖像生成流程和技巧
.png)
前言
此篇測試本地 stable-diffusion-xl-base-1.0 的推論效果,使用 GPU RTX 3060 進行推論
進行本地圖片生成推論可以滿足大部分的商業、個人或團隊使用需求,以及後續的技術積累
認識以下知識將更順利的進行
- 硬體設備 選擇運算方式如GPU、NPU、CPU,留意記憶體配置,用於主力運算伺服器或是小型邊緣AI設備
- 軟體工程 熟悉軟體工程的環境套件以及基本邏輯,理解AI所回應的程式碼細節,自行優化調整,或是要求AI進行不同需求的改正
- 圖像的語意 例如平面設計、遊戲開發、攝影、藝術等等的專有名詞,prompt 語意輸入可以讓 AI 模型推論神經網路的向量,推導相同類型的權重,從而生成出該效果
環境套件
請挑選當前版本以及適合自己得配置來安裝,以下是環境套件的官方連結
- pytorch https://pytorch.org/get-started/locally/
- stable-diffusion-xl-base-1.0 https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
- stable-diffusion-xl-refiner-1.0 https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
目錄
- Stable Diffusion XL 模型介紹
- Stable Diffusion XL 本地模型運行
Stable Diffusion XL 模型介紹
SDXL(Stable Diffusion XL)是由 Podell 等人於 2023 年提出的高階潛空間擴散模型(Latent Diffusion Model, LDM),用於文字轉圖像合成(Text-to-Image Synthesis)。相較於 Stable Diffusion 1.5 與 2.1,SDXL 採用三倍規模的 UNet 架構,並引入了更多 注意力模組(Attention Blocks)與跨注意力上下文(Cross-Attention Context)。此外,該模型結合雙文字編碼器(CLIP ViT-L 與 OpenCLIP ViT-bigG),進一步提升了語意理解能力。
圖像生成流程如下所示:
- 第一步:SDXL 生成 的潛在特徵(Latent Representation)
- 第二步:使用高解析精煉模型(Refinement Model),搭配相同文字提示(Prompt),對潛在表示進行 SDEdit(Stochastic Denoising Edit) 運算,提升細節與寫實度
兩個階段皆使用相同的自編碼器(Autoencoder)進行潛空間與像素空間的轉換,此設計大幅提升最終圖像的解析度與美學品質,同時保留原始語意一致性。
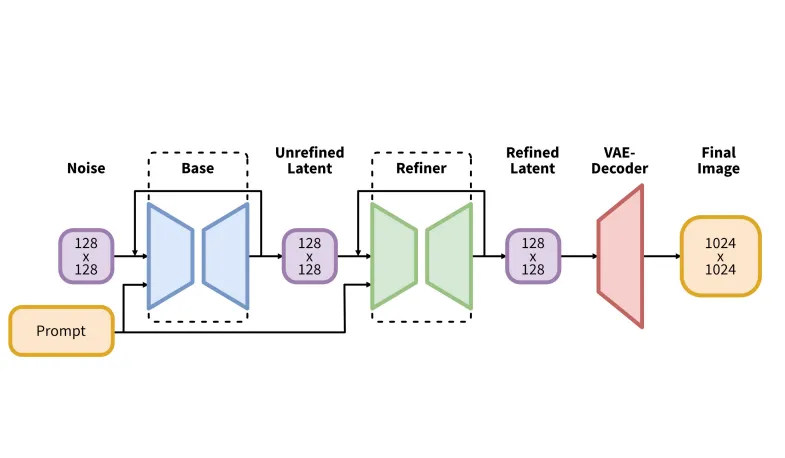 [1] 圖片來自於 Podell et al. (2023) 所提出的 SDXL 模型架構圖(摘自 arXiv:2307.01952)
[1] 圖片來自於 Podell et al. (2023) 所提出的 SDXL 模型架構圖(摘自 arXiv:2307.01952)
模型參數
這個版本使用了更大的參數,以提升神經網路的表現能力與學習容量,從而能更有效地捕捉文字與圖像之間的複雜關聯,並生成更高品質的影像。
SDXL相較於過去版本的參數數量:
| 模型版本 | UNet 參數數量 | 備註 |
|---|---|---|
| SDXL | 2.6B | SDXL 主模型 |
| SD 1.4 / 1.5 | 860M | 約為 SDXL 的三分之一 |
| SD 2.0 / 2.1 | 865M | 架構與 SD 1.5 相近,改用不同文字編碼器 |
Stable Diffusion XL 本地模型運行
本次使用的模型是 Stable Diffusion XL 模型連結放在環境套件中,可以參考Hugging Face官方提供的基本架構,SDXL模型提供以封裝的方法,能使用簡短的程式碼來使用
這部分記錄實際的基本流程觀念
stable-diffusion-xl-base-1.0
一開始可以先調整 num_inference_steps = 30 較少的推論時間,用於大致預覽 prompt 的描述是否是我們想要的 ,大部分的主流模型都有 seed ,當該圖片整體構圖是理想的時候,可以使用相同的 seed 來生成類似的圖片,否則每一次都是隨機的構圖
重點參數
prompt = """
cyberpunk city, cafe at night,high-rise view, low-key lighting, large advertising projection billboard
"""
negative_prompt = """
perple tone
blurry, low quality
"""
height = 1152
width = 1536
num_inference_steps = 30
模型物件
base = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16" ).to("cuda")

在確認圖片的架構後,選擇一樣的 seed 再重新推論一次,只是這次調整 num_inference_steps = 100
可以觀察出經過更多次的推論後,圖像有了更多改動,如右上角的延伸,但是整體結構不變,這是seed 所固定的構圖、輪廓、結構

stable-diffusion-xl-refiner-1.0
在剛剛所使用的是 stable-diffusion-xl-base-1.0 用於生成整體圖片如構圖、輪廓、結構等等,而這部分則使用SDXL所提到可以搭配使用的 stable-diffusion-xl-refiner-1.0 模型用於的細節
再來是在原本的 prompt 添加上兩個詞,分別是 cel shading monochrome color palette ,使用專有名詞或是術語很好調整AI對於圖像所生成特徵,例如 cel shading 是遊戲引擎中的卡通渲染
,進行重新推論,圖片效果如下

結語
SDXL 為較寫實的模型,因此若是較為風格化的需求,在prompt的處理上會比較麻煩些,尤其是對於 語意過於 抽象、不具體、過多語意表達,容易造成圖像生成異常,因此選擇符合貼近需求的模型,會比不斷調整 prompt來的更容易,此外大部分圖像生成品質不好多半是 prompt 和 negtive prompt 寫的過多過於複雜,是當精簡語意讓模型權重更好的收斂會是更好的調整方向。
參考
[1] Podell, Dustin, et al. "Sdxl: Improving latent diffusion models for high-resolution image synthesis." arXiv preprint arXiv:2307.01952 (2023).


