【論文概念】A diverse ensemble classifier for tomato disease recognition
版權與使用聲明
此文章主要目的為學術概念、方法紀錄,以及心得觀點。
本文將遵守著作權法,依合理使用原則(如學術引用、評論等目的)撰寫。
如有引用圖片,均依原始授權條款(如 Creative Commons、Open access)使用。
如需完整研究細節、圖表與原始內容,請參考原始論文出處。
論文出處
Mounes Astani, Mohammad Hasheminejad, Mahsa Vaghefi, A diverse ensemble classifier for tomato disease recognition, Computers and Electronics in Agriculture, Volume 198, 2022, 107054, ISSN 0168-1699, https://doi.org/10.1016/j.compag.2022.107054
摘要與結論
該研究在分類實驗室和⽥野環境中 13 種番茄疾病類別,並使⽤了兩個資料庫,包括 Plant Village 與台灣番茄葉片
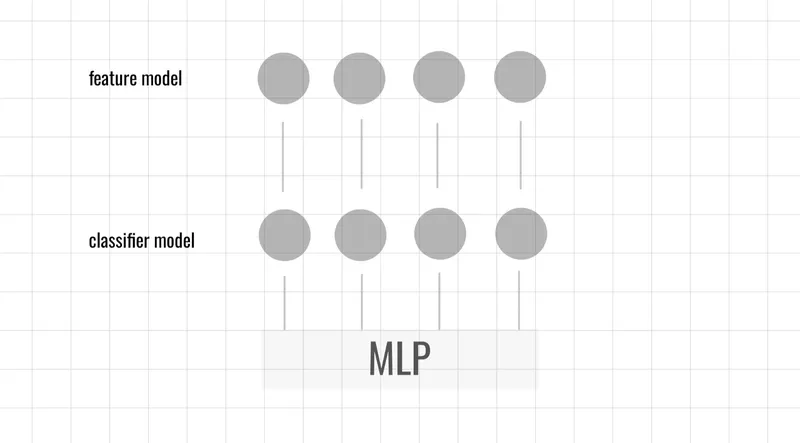
主要講述了影像特徵工程的資料處理方法,設計組合模型方法,分別是特徵模型與分類模型的不同組合方式,是一種集合模型,用多層感知器MLP進行深度神經網路訓練,透過組合調整方式來提高彈性空間。
在評估上使用了混淆矩陣(confusion matrix)這項評估指標,來進行精確度評估,並視覺化了260種組合的精確度,驗證了不同組合所能帶來的影響
最終證明了在 260 個案例中,藉由建⽴預處理、特徵以及不同分類⽅式與 MLP 結合規則,能夠以 95.98% 的精確度分類,模型的訓練時間僅需 74.3 分鐘,比深度模型更快,特定組合在精確度和效能上的優異表現,以及成功將模型輕量化,更適合在農場這類電腦運算能力不足的場景也能順利進行工作。
提出在未來,可透過創造不同的多樣性,或改變分類器數量來檢驗所提出的⽅法
介紹
番茄是全球主要作物之一,因此準確且即時的病害診斷顯得重要,隨著人工智慧與影像處理技術進步,加上大型影像資料庫的可用,能更容易地幫助農業診斷與分類植物病害。
不過病害診斷仍具挑戰性,例如需要考慮陰影、亮度變化、背景雜訊與遮擋、病徵隨時間變化、不同病害相似性高,以及跨資料庫影像特徵不一致等問題
資料集
該研究旨在對農場和實驗室條件下的番茄葉片病害進行診斷和分類。所提出的方法結合使用了兩個資料庫,包括 Plantvillage 和台灣番茄葉片。
Plantvillage 資 料庫包含⼗個類別(九個疾病類別及⼀個健康類別),台灣番茄葉⽚資料庫則有六個 類別(五個疾病類別及⼀個健康類別)
兩個資料庫的影像均調整為 256 × 256,並使⽤兩個資料 庫的增強影像。具備數據增強的兩個資料庫影像數量如表 5 所⽰
台灣番茄葉片和 Plantvillage 資料庫中包含 12 個病害類別和 1 個健康類別,每個類別包含資料增強影像數量。
其中 80%⽤於訓 練,20%⽤於測試
方法
在講架構之前,這裡有本次研究所使用到的現有的特徵提取模型,這裡簡稱為模型A、B、C、D,以及分類模型RF, SVM, LR, K-NN,後續會不斷提及這些關鍵字
特徵提取模型
主要使用到現有的特徵提取模型有 A: K-means 聚類 B: 對比度增強、對顏色、紋理、幾何特徵進行特徵提取 C: 陰影去除以及尺度固定特徵轉換 D: 背景去除,去除圖像雜訊,進行影像對比增強
分類器模型
使用到的四種分類模型分別有 RF, SVM, LR, K-NN
架構
主要有三個流程分別是預前數據處理、特徵提取、分類器,透過不同的組合規則進⾏檢驗,最終使用MLP來進行最終預測
該研究透過不同特徵提取與分類器選擇,進行了多達260種的組合策略
評估
這部分是經典的準確度與精確度的評估方式,使用在很多論文中
準確度的評估方式為,計算正確地預測出病害樣本TP,正確的預測出健康樣本TN,再除以所有檢測出的樣本總數
模型的預測結果分為四種狀態 TP: 正確地預測出病害樣本 TN: 正確的預測出健康樣本 FP: 錯誤的預測出病害樣本 FN: 錯誤的預測出健康樣本
準確度(Accuracy)
模型正確地預測為病害樣本(TP)與健康樣本(TN)的總數,除以所有樣本總數。
精確度(Precision)
精確度衡量的是被模型判定為病害樣本中,有多少是真的病害樣本,指被判定出病害的樣本數,公式表達為TP正確除以預測病害總數
結果評估
本論文透過基本的固定數與控制條件變數來觀測訓練結果,最終找出當前最佳準確度模型,實驗評估多達260種組合。
第⼀次⽐較
使用了相同特徵模型與相同分類器來進行比較
預測1到預測4中,特徵模型順序為 A、B、C、D 使用 RF分類器
後續至預測20中,每一次循環都使用不同的分類器,分別為RF、LR、K-NN、SVM
實驗透過固定分類器的組合,指改變特徵模型的組合來觀測,A、B、C、D之間的關係
第⼆次⽐較
使用了4種不同的特徵模型與相同分類器
第二次則是與第一次相反,透過固定特徵模型( A、B、C、D )來觀測不同分類器(RF、LR、K-NN、SVM)之間的關係
第三次⽐較
使用了4種不同的特徵模型與4種不同的分類器
這是重要的一次比較,因為從結果得出了最高的精確度,該組合為 Predict 35 (A + LR、B + K-NN、C + RF、D + SVM)
因此,這也表示四種模型+四種分類器的設計,提供最大的特徵多樣性與最高的準確度
其他多次比較
後續的比較總數多達260種組合,後續的評估比較都為了更好的支撐,組合多樣性的觀點,最終得出以模型多樣性的特徵模型與分類器的組合,可以達到最高準確度。
其他深度學習模型的⽐較
比較其他深度模型(Efficient B4、Xception、DenseNet169 InceptionResNetV2)的運行效能,與該研究所提出的集成策略模型,結果表示在硬已的限制下,運用集成策略明顯的降低了運行推理時間和不同組合彈性,並且仍可達到高度準確率的成果,這也使的農場可以在硬體的限制下,順利執行番茄病害檢測任務